The other day I struggled a bit as I was trying to get something to work on the out-of-the-box Windows Subsystem for Linux that ships as Ubuntu. Linux is Linux, but Ubuntu is just a bit different from Oracle Linux (basically RHEL with some better stuff) that I use daily.
Since I didn’t have anything really configured in my current WSL, I just removed the Unbuntu Linux and installed Oracle Linux. It’s pretty awesome to have my WSL match the distribution that I use every day.
The default display for the database for date columns is often DD-MON-RR. So Januray 1st, 2021 would display as 01-JAN-21. This is horrible. The time portion of the date is missing from the display (an Oracle date is always composed of at least the century, year, month, day, hour, minute, and second) and the RR format will lead to issues in 2050 which isn’t that far away.
To get your Oracle tools (like sqlplus and rman for example) on your Unix/Linux server to show dates in a better format, the following will help.
One of my customers is deploying a new driver for their VMWare Cluster SAN next week. The last time they did this (about a year ago), there were random disk corruptions on the database servers. Needless to say, this was bad.
This time the VMWare team is going to be on the lookout for corruption, but the database team wanted to also do an extra check and run an rman validate command on the “datafiles with the most write activity”.
The following query will give you a list of tablespaces with write activity over the last hour with the highest write activity.
select tablespace_name , sum(physical_block_writes) as total_last_hour_block_writes
from v$filemetric_history
join dba_data_files using (file_id)
group by tablespace_name
having sum(physical_block_writes) > 0
order by sum(physical_block_writes) desc;
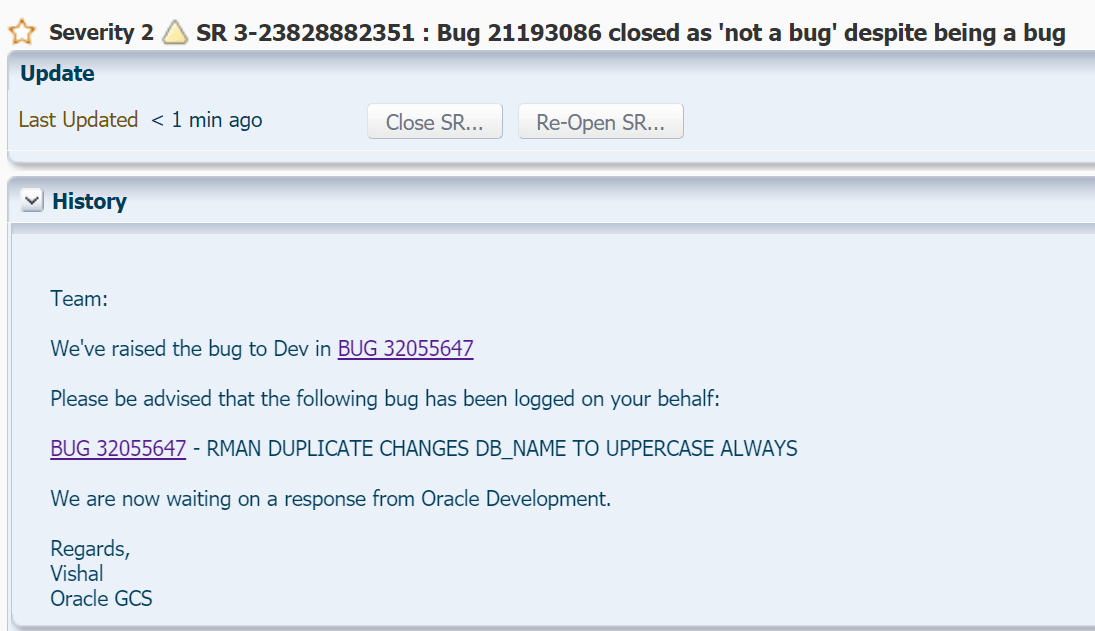
I’ve been working with RMAN for quite a while and one thing that has always annoyed me is if you create a database using the RMAN duplicate command, it will always change your DB_NAME to uppercase. Someone logged a bug against this a long time ago and it was closed as ‘not a bug’ because “Doc ID: 2050095.1 Due to many dependencies, RMAN needs to convert DB_NAME and DB_UNIQUE_NAME to UPPER case. This is confirmed by development via Bug 21193086 closed as ‘not a bug’.”
A while ago, during a marathon RMAN duplicate session with a customer, I decided to go ahead and raise the bug again.
I filed the SR above and included the following:
While closed as ‘not a bug’, it most definitely is a bug. There are MANY ramifications of this including scripts, database directory objects (/u01/app/oracle/admin/orcl/dpdump becomes /u01/app/oracle/admin/ORCL/dpdump for example), wallet locations, etc.
Just because whoever wrote this code way back when made a few mistakes doesn’t mean that this isn’t a bug. It is a bug. You are taking a duplicate (clone operation) and arbitrarily changing things that shouldn’t be changed. I spend 14.5 years at Oracle including 5.5 years in development. Far too often there was a joke about “I just status 32’d the issue. If they really care, they’ll raise it again.”
There can’t really be ‘many dependencies’ since this only happens in the very final stage of an RMAN duplicate.
Consider this the “it was raised again”.
After quite a while (and I do mean quite a while) the support team raised my bug with the Oracle development team.
I’m really hoping that the development team comes up with a better solution than they did for the old bug. While you need a support contract to see the solution in Doc ID 2050095.1, if you imagined a scenerio where Oracle said “Deal with it”, you wouldn’t be far off from their current ‘solution’.
I asked Oracle to publish the bug, and they have… Here’s to hoping this gets addressed.
Today I finished off a project where I migrated a database from a non-container 12.1.0.2 database to a pluggable 19.9 database. The final step: run noncdb_to_pdb.sql.
I’ve been using SQLcl without any issues, but for some reason SQLcl (20.2, the latest version) produced an error where SQL Plus didn’t!
SYS@CDB$ROOT AS SYSDBA> STORE SET ncdb2pdb.settings.sql REPLACE
SP2-0603: Illegal STORE command
Usage: STORE {SET} filename[.ext] [CRE[ATE]|REP[LACE]|APP[END]]
SQL Plus on the other hand ran the same command just fine:
SYS@aurdcon AS SYSDBA> STORE SET ncdb2pdb.settings.sql REPLACE
Wrote file ncdb2pdb.settings.sql
Today I took the DBA Masterclass Quiz (truthfully just a bit too easy…) and earned the above badge from Oracle.
Oracle put on a three class event that was fun and informative. You can watch the recordings even though the live presentations are finished.
For me, one of the best outcomes was connecting directly with Russ Lowenthal (@RussLowenthall), a member of the Database Security Team, and have a great conversation about fixing the whole tls_wallet (or ssl_wallet if you are a bit older) issue with requiring DBAs to download root and intermediate certs so that the database can access TLS encrypted URLs. I presented Russ with some interesting ideas which he said the database team at Oracle would consider for future releases. Basically we’d all like the ability for the database to ‘just work’ with signed URLs the same way your browser just works.
Here’s to hoping the security team gets around to fixing this!
Oracle backup terminology can be kind of confusing. And, by can be, I mean that it is confusing. There are lots of different terms that sound similar but mean very different things. I’ve seen very experienced DBAs use the following statements synonymously: “I just did a whole backup” and “I just did a full backup”. The correct response to “I just did a whole backup.” is “Thanks! I appreciate it.”, while the correct response to “I just did a full backup.” is “Of what?” or maybe even “Why?”. Because, according to Oracle’s terminology, those two statements mean quite different things.
I’ll be defining the terminology that Oracle uses in their training material and documentation and, in addition, making suggestions on what your backups should most often look like.
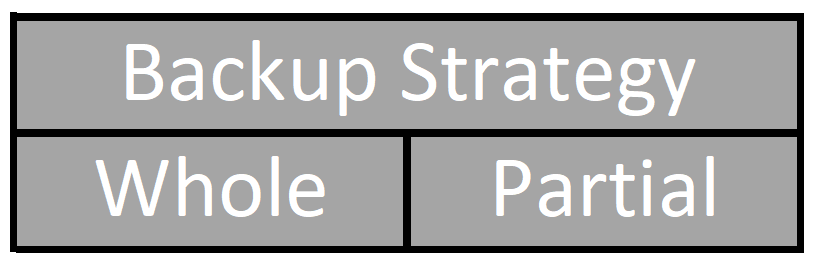
Backup Strategy – Whole or Partial
Every Oracle backup is either a whole backup or a partial backup.
A whole backup in Oracle terminology means that you’ve backed up all data in all datafiles and at least one control file. Since the control files (you have configured multiple control files, right?) are copies of each other, you technically only have to backup a single control file.
So what is a partial backup? It’s a backup that isn’t all data in all datafiles and a control file, but instead less than that. If you backup a single datafile, you’ve done a partial backup. If you backup all datafiles but one, you’ve done a partial backup. If you backup all data in every single data file, but don’t back up at least one control file, you’ve done a partial backup.
Backup strategy tells you how much of your database you are backing up. You are either backing up all data in all datafiles and at least one control file, or you are backing up something different than that.
For your backup strategy you should start with a whole backup of your database. After that initial backup you can either do partials forever using the Oracle Suggested Backup Strategy , or you can bounce back and forth between whole and partial backups. To me, the least effective backup strategy is to always do whole backups, but some folks do use this strategy. I much prefer to start with a whole backup and then do partial backups from then on using the Oracle Suggested Backup Strategy.
As an aside, notice that a whole backup doesn’t technically need an spfile to be included in the backup, but I always include an spfile in all my whole backups.
Backup Type – Full or Incremental
The next term that Oracle uses to describe a backup is Backup Type. Every backup is either a Full Backup or an Incremental Backup.
And… Welcome to the start of the confusion! Whole does not equal Full. While you can do a whole full backup, you can also do a partial full backup.
Backup type tells you how the backup can be usedrelative to other backups. Generally, a full backup stands on it’s own and isn’t used in conjunction with other backups. A full backup backs up all the data in whatever you are backing up. An incremental backup canbe used with other incremental backups and, depending on it’s level (which I’ll explain in a moment) either backs up all the data in whatever you are backing up, or all the data that has changed since your previous incremental backup.
To further increase backup type complexity, incremental backups have different types themselves. Incremental backups are either a Level 0 backup or a Level 1 backup. And, to make backup types even more confusing, Level 1 backups are also of different types! Incremental Level 1 backups are either Cumulative or Differential backups.
Let’s start with a Level 0 backup. A Level 0 backup is identical to a full backup in that it contains all of the data in whatever you are backing up (remember, it could be either a whole or partial backup that you are doing), but it has one additional property: It can be used as the base backup for later incremental level 1 backups.
A Level 1 backup contains only data that has changed since a previous backup. Which previous backup? Well, it depends on the incremental Level 1 backup type. If it is an incremental Level 1 Cumulative backup, then it will always contain the changes since the last Level 0 backup. An incremental Level 1 Differential backup, on the other hand, will contain the changes since the previous incremental backup whether it was a Level 0, Level 1 Cumulative, or Level 1 Differential.
One might ask: Why do we have these two different Level 1 backup types?
It’s basically a balance between the size and speed of the backup (the first differential or cumulative backup taken after a level 0 backup are the same, but, generally subsequent differentials should be faster and smaller than subsequent cumulative backups), and the time to recover datafiles past the level 0 restore point. A recover process of a single cumulative backup should be faster than recovering 6 differential backups. However, if you have almost all add operations, then the difference could be negligible. If you have many update operations, then the difference could be significant.
These days we don’t really have to worry about this so much. Most of the time, we just do differential backups when we do level 1 backups because the files that make up the backup are usually located in one place instead of separate physical tapes and we don’t have to mount and unmount tape drives any more, or if we do, the capacity is massive compared to the early days of computing and we are not bouncing from tape to tape like we did in the past.
For backup types, I always start with an incremental level 0 backup. In general, I don’t usually do full backups. Since an incremental level 0 is nothing more than a more flexible full backup, a whole incremental level 0 is usually the way to go for a base backup. Once that is completed, I usually follow that up with incremental level 1 differential backups and then move my level 0 backup forward in time by applying previous level 1 incremental backups to the level 0 backup, effectively moving the level 0 backup forward in time.
Backup File Type – Image Copy or Backup Set
So… Here’s another source of confusion. Backups generate output files, and there are two different types of output files: Image Copies or Backup Sets.
An image copy (which RMAN, the tool Oracle supplies to manage and use database backups, just shortens to COPY) is an exact bit for bit duplicate of the file. It includes all used and unused space in the file. So, if you’ve created a 1 TB datafile and only have 10 MB of data in it and you create an image copy backup of this file, you’re output file will be… 1 TB.
With backup sets, instead of taking an exact copy of the whole file, Oracle just extracts the actual information from the file and then creates a new file (or multiple files if specified and/or necessary) that contains the necessary information. Additionally, this file can also be compressed, so it is often much, much smaller than an image copy backup. That 1 TB datafile with 10 MB of data in it backed up as a backup set could, potentially, be even smaller than 10 MB.
Further more, image copy backups are always either full backups or incremental level 0 backups. If you have an incremental level 1 backup (either kind!), then it can’t be an image copy (it only has information that has changed since a previous backup) and therefore it will always be a backup set.
Since backup sets are so efficient, one might wonder why you’d ever create an image copy. It turns out that the efficiency of a backup set (much less storage used for the backup) is limited to the creation process. When it becomes time to recreate the original file (called a restore in Oracle terminology, which is done from either a full or incremental level 0 backup) all the data in the backup set must be read and the original file is recreated step by step until you have a copy of the file at the point in which it was backed up. With a restore we are going to create a bit for bit copy of the original file at the time of the backup… and that is exactly what an image copy is! So, instead of recreating the original file, if you have an image copy backup, you can actually point to the image copy and tell the database to use it directly. This means that the time to restore the file from an image copy can be effectively instantaneous. The time to restore a file from a backup set depends on the size of the backup set, so as your backups get bigger, your restore time gets longer if you are using backup sets.
The computer science way of saying this is:
A restore operation of an image copy backup can be an order 1 operation. Using the RMAN switch command, the amount of time to restore a 1 MB datafile is the exact same amount of time to restore a 32 GB datafile.
A restore operation of a backup set is always an order N operation. We can’t switch to a backup set, so we’ll have to read all the data and recreate the datafile from scratch. So a 1 MB datafile will restore much more quickly than a 32 GB datafile.
Backup File Destination – Disk or Tape
In the earlier days of computing computer storage was broken into two distinct buckets: Disks which were faster but extremely expensive per storage unit, and tapes which were slower but much less expensive per storage unit. These days the lines between disk and tape have become a bit blurred with cloud backups that can appear as either disk or tape and could go (on the cloud) to disk or tape under the covers (under the cloud?). Also, the cost differences generally favor tape.
As far as Oracle backups go, backups are written to one of two different devices: DISK (self explanatory) and SBT (which stands for System Backup to Tape). It’s important to understand that these device types are logical rather than physical. If you configure some AWS or Oracle Cloud Object Storage in the cloud as a local drive mounted to your computer and do a disk backup to it, as far as Oracle is concerned the backup went to disk (even though it went to ‘the cloud’). If you configure a the SBT driver to point to some disks, Oracle will consider the backup written to this device to be a tape backup. The Oracle Database Cloud Backup Module, for example, turns cloud storage into a ‘logical tape drive’.
Backups to the logical device type disk can be either image copies or backup sets. Backups to the logical device type SBT however can only be backup sets.
So, it seems kind of clear: You can backup up to image copies or backup sets to disk, and backup sets can go to tape… but, guess what (remember, this can be a bit confusing). It turns out that there are two different kinds of ‘device type disk’ backups. Oracle gives you the ability to define a special disk location called the fast recovery area. Of course, just to make things fun, when this special location was first introduced it was called the flash recovery area. When Oracle introduced this term it was before the dawn of flash disks (usually called solid state drives now). Since this could be confusing(!), Oracle decided to change the name of the flash recovery area to the fast recovery area. At least the abbreviation for the fast recovery area is the same as it always was: FRA.
So, what’s the difference between a disk backup to the FRA and a disk backup to ‘not the FRA’? Really, nothing. They are the same. There is no ‘different information’ in a backup to the FRA vs. a backup to ‘not the FRA’. However, backups to the FRA are managed differently by Oracle.
The FRA is defined by setting two Oracle database parameters (not RMAN configuration settings as one might expect): DB_RECOVERY_FILE_DEST which points to a location logically on the server, and DB_RECOVERY_FILE_DEST_SIZE which determines how much space is logically allocated for this particular database to use. It’s important to realize that the db_recovery_file_dest_size is logical, not physical. This means that if you point to a mount point (let’s say you set db_recovery_file_dest to /u02/app/oracle/fast_recovery_area) that has 1 TB of storage allocated to it, but you set the db_recovery_file_dest_size to 2 TB, Oracle won’t complain in the least… until you actually write more than 1 TB of information to the FRA. At that point you’ll get some out of space errors from the OS and whatever operation Oracle was trying to do in the FRA will fail. So, obviously, that would be just silly to do. Let’s assume that you are going to set your FRA logical size to be something that makes sense for the system you are running Oracle on. What does using this ‘logically identified and size space’ get you? Well, if you put items into the FRA and they are no longer needed to meet your retention targets (these are defined with RMAN configuration settings) then Oracle will, if it can, automatically remove no longer needed items for you. If you do not have those two database parameters set then your disk backups go to ‘not the FRA’ and you have to manually maintain the space. If you do have those two database parameters set, and you do a disk backup to ‘someplace other than the FRA’ then again, you’ll have to manually maintain the space.
So far we have covered the following Oracle Backup Terminology:
Backup Strategy
Whole
Partial
Backup Type
Full
Incremental
Level 0
Level 1
Differential
Cumulative
Output File Type
Backup Set
Image Copy
Output File Location
Tape (SBT)
Disk
FRA
not FRA
For now, this seems like quite a bit of ground to cover, and this post is getting quite long. At some point in the future I’ll attempt to cover other things like the following:
Database Log Mode
ARCHIVELOG
NOARCHIVELOG (I call this ‘polish your resume mode’.)
After watching a client pipe the results of a find command into a text file, and then edit the text file to add rm in front of each line and then turn the text file into a script and run it… I knew I needed to add this here.
Sometimes you have too many audit logs and rm *.aud returns the following:
The introduction of container databases in Oracle 12.1 created a whole new world of Oracle Databases dividing them into non-Container Databases (we’d been using these all the way through Oracle 11g, we just didn’t know it) and Container Databases.
Starting with Oracle 20c all Oracle Databases will be container databases, so we’ll no longer be able to stick with the (to many at least), more familiar non-Container Database architecture.
Note: A multitenant container database is the only supported architecture in Oracle Database 20c. While the documentation is being revised, legacy terminology may persist. In most cases, “database” and “non-CDB” refer to a CDB or PDB, depending on context. In some contexts, such as upgrades, “non-CDB” refers to a non-CDB from a previous release.
Great! That won’t be confusing at all… (Yes, I’m being sarcastic). Hopefully, the documentation will be revised very quickly.
I’ve been teaching the Oracle Education Oracle Database: Managing Multitenant Architecture course ever since the release of 12.1 and I’ve additionally been managing multitenant container databases for multiple customers for many years now.
Over the years I’ve seen many different naming conventions for naming multitenant container databases and the pluggable databases that are deployed inside them.
Oracle, and many of Oracle’s customers, have been referring to the Root Container (CDB$ROOT) of a container database as the CDB, and the pluggable databases inside a container database (which, according to the Oracle documentation are also containers themselves) as a PDB.
One big issue with the CDB/PDB terminology is that it can be hard, at least in English, to distinguish between CDB and PDB when speaking. So, naming a container database cdb1 and naming a pluggable database inside of it pdb1 can make things very hard to understand when having conversations about container databases. “Wait, did you say cdb? Or pdb?”
The container database architecture is really designed to be used with the clients and/or applications connecting to the pluggable databases as if they were the old style stand-alone databases (or non-container databases are they are now called). Generally, nobody except the DBA team is going to be connecting to the root container. Additionally, and probably most importantly, regular database users and/or applications don’t care that they are connecting to a pluggable database. So, adding pdb as a suffix to all your pluggable databases really doesn’t add any value.
I feel pretty confident that the current naming scheme that I’m using with many of my customers actually works in real life. It’s basically two rules:
Rule One:
Name the actual container database with a “con” suffix.
Rule Two:
Name the pluggable database what you would have previously named a standalone database and never add a pdb suffix or prefix.
Let’s look at some examples:
You want to create a ‘playground’ database named orcl.
The root container would be named orclcon and there would be a single pluggable database named orcl.
You want to create a container database on a production server.
The root container would be named prodcon and there would be a pluggable database named prod.
You only have one database server (and therefore it is the production server), but you want three databases, prod, test, and dev.
The root container would be named prodcon and there would be three pluggable databases: prod, test and dev.
You have three database servers, let’s say dev, test, and prod.
Three container databases named devcon, testcon and prodcon, one per server, each containing a single pluggable named dev, test, and prod respectively.
Here, however, things could get a bit more interesting. Let’s say we decide to give each developer their own pluggable database. Our dev team is composed of Jill, John, and Jane. We’d still have devcon as the name of the container database that supports development databases, but instead of a single pluggable named dev, we’d have three pluggables named jill, john, and jane.
Now let’s say that on your test server, you decide that you are going to have four databases: test, integration testing, quality assurance, and training. We’d still have testcon as the name of the container database, but we’ll now have four pluggables named test, int, qa, and train.
After playing with different naming schemes over the years, I’ve found that the naming scheme above works the best in the real world.
Every once in a while I’ll be in the situation where two things intersect: I’ll want to log into the database using the command line directly (using sqlplus, sqlcl, expdp, rman, etc.) and someone has created a password with spaces in it for the user I want to connect as.
One might assume that you’d only have to escape the double quotes around the password (using \” ), but it turns out you actually need to provide an extra set of double quotes around the password when it has spaces in addition to the escaped double quotes.
[oracle@thecloud ~]$ sqlplus sys@orcl as sysdba
SQL*Plus: Release 18.0.0.0.0 - Production on Sat Dec 14 06:14:33 2019
Version 18.6.0.0.0
Copyright (c) 1982, 2018, Oracle. All rights reserved.
Enter password:
Connected to:
Oracle Database 18c EE Extreme Perf Release 18.0.0.0.0 - Production
Version 18.6.0.0.0
SYS@orcl AS SYSDBA> create user bob identified by "Password with spaces";
User created.
SYS@orcl AS SYSDBA> grant create session to bob;
Grant succeeded.
SYS@orcl AS SYSDBA> exit
[oracle@thecloud ~]$ sqlplus bob/\""Password with spaces\""@orcl
SQL*Plus: Release 18.0.0.0.0 - Production on Sat Dec 14 06:18:26 2019
Version 18.6.0.0.0
Copyright (c) 1982, 2018, Oracle. All rights reserved.
Connected to:
Oracle Database 18c EE Extreme Perf Release 18.0.0.0.0 - Production
Version 18.6.0.0.0
BOB@orcl > exit
If bob’s password was just Password and not “Password with spaces” then we’d be able to connect using either of the below:
[oracle@thecloud ~]$ sqlplus bob/Password@orcl
SQL*Plus: Release 18.0.0.0.0 - Production on Sat Dec 14 06:18:26 2019
Version 18.6.0.0.0
Copyright (c) 1982, 2018, Oracle. All rights reserved.
Connected to:
Oracle Database 18c EE Extreme Perf Release 18.0.0.0.0 - Production
Version 18.6.0.0.0
BOB@orcl > exit
[oracle@thecloud ~]$ sqlplus bob/"Password"@orcl
SQL*Plus: Release 18.0.0.0.0 - Production on Sat Dec 14 06:18:26 2019
Version 18.6.0.0.0
Copyright (c) 1982, 2018, Oracle. All rights reserved.
Connected to:
Oracle Database 18c EE Extreme Perf Release 18.0.0.0.0 - Production
Version 18.6.0.0.0
BOB@orcl > exit
Once the password has spaces in it, you must include the ‘double double quotes’ and escape the first set of quotes as in the first example.